
*이 글은 Tacademy의 'R로 하는 텍스트 데이터 전처리 방법' 강의를 듣고 작성했습니다.
📂 사전지식
💾 tidyverse 패키지
1. RStudio가 개발, 관리하는 패키지로 공식문서 good
2. 6개의 핵심 패키지 포함 23가지 패키지로 이루어진 메타 패키지(종합 솔루션 느낌)
3. 중심이 되는 dplyr 패키지는 데이터를 다루는 문법의 일종 (tidyverse 문법 스타일 권장)
4. tidy data 라는 사상과 파이프 연산자는 세트로 같이 쓰임
💾 파이프 연산자 %>%


점점 함수를 중첩해 사용할 일이 빈번해지는데, ((( ))) 형식으로 작성하면 가독성이 현저히 떨어진다.
이럴때 %>% 파이프 연산자를 사용하면 생각의 순서대로 함수를 작성할 수 있고, 중간 변수를 저장할 필요가 없어진다.
사용할 데이터부터 순서대로 함수를 작성할 수 있는 장점이 있음.
💾 dplyr 패키지
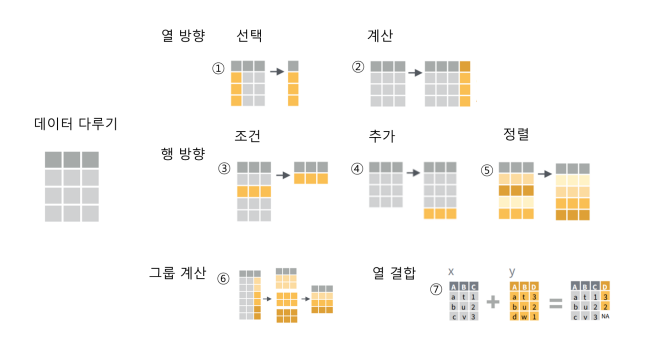
데이터를 다루는 주요 7가지 동작 + 추가적인 helper 함수 제공
- 열 방향 : 선택 - select(dataset, col1, col2, ...)
- 열 방향 : 계산 - mutate(dataset, speed = distance / air_time * 60)
컬럼과 컬럼을 이용해 새로운 컬럼을 계산해낸다(컬럼 간 연산으로) - 행 방향 : 조건 - filter(flights, month == 1)
논리연산자와 결합하여 사용함 (True/False로 리턴되는) - 행 방향 : 추가 - bind_rows()
column 이름이 달라도 일단 무조건 합침 (데이터를 확인해보는 과정을 거쳐야함) - 행 방향 : 정렬 - arrange(flights, arr_time)
- 그룹 계산 : group_by() + summarise()
그룹이 걸려있는 상태인지 아닌지를 알고 있어야 함(ungroup) - 열 결합 : left_join()
💾 단정한 데이터(tidy data)
freesearch.pe.kr/archives/3942
cran.r-project.org/web/packages/tidyr/vignettes/tidy-data.html
1.1 Each variable forms a column.
1.2 각 변수는 개별의 열(column)으로 존재한다.
1.3 각 열에는 개별 속성이 들어간다.
2.1 Each observation forms a row.
2.2 각 관측치는 행(row)를 구성한다.
2.3 각 행에는 개별 관찰 항목이 들어간다.
3.1 Each type of observational unit forms a table.
3.2 각 테이블은 단 하나의 관측기준에 의해 조직된 데이터를 저장한다.
3.3 각 테이블에는 단일 유형의 데이터가 들어간다.

long form = tidy data
- 컴퓨터가 계산하기 좋은 모양
- tidy data의 요건을 충족
- tidyverse 패키지 대부분의 입력 형태
wide form
- 사람이 눈으로 보기 좋은 모양
- 2개 변수에 대한 값만 확인 가능
- dashboard형, 조인 등 연산이 어려움
💾 Token 이란?
글자 중 의미를 가진 단위의 총칭
영어는 tokenize가 엄청 발달되어있지 않다. (띄어쓰기로 tokenize 가능)
tokenization은 가지고 있는 텍스트 자원을 token 단위로 나누는 것을 말한다.
ex. 자소(자음, 모음), 음소(글자), 형태소, 단어, n-gram 등
- a table with one-token-per-row
- 한 행에 한 토큰으로 테이블을 구성해야 한다
install.packages("tidytext")
library(tidytext)
unnest_tokens(
tbl = 다루고자하는 텍스트 데이터 객체,
output = 토큰화의 결과가 작성될 새로운 열이름,
input = 토큰화 하고싶은 텍스트 컬럼명,
token = "words", (기본값(words 단위 = 띄어쓰기 단위)이 있어 생략가능)
...
)unnest_tokens() 함수는 텍스트 데이터를 token 단위로 풀어낸다.
install.packages("N2H4")
library(N2H4)
library(dplyr)
tar <- "https://news.naver.com/main/ranking/read.nhn?mode=LSD&mid=shm&sid1=001&oid=437&aid=0000261701&rankingType=RANKING"
getAllComment(tar) %>%
# select(userName, contents) %>%
unnest_tokens(ws, contents, "words") #output=ws, input=contents, token="words"

띄어쓰기 단위로 토큰화하도록 unnest_tokens 함수를 적용해봤다.
하지만 이렇게 띄어쓰기를 단위로 하면 데이터가 sparse 해진다.

💾 형태소 분석
한글의 특징 형태소 (형태소: 의미를 가지는 최소 단위)
N(체언=명사)과 P(용언=동사+형용사)만 알아도 많은 걸 할 수 있다.
- R의 대표적인 형태소 분석기
- RmecabKo
1. 일본어 형태소 분석기인 mecab 기반2. c++ 형태로 작성하여 속도가 매우매우 빠름 but 좀 더 sparse한 결과를 낸다
3. 일본어, 중국어 등도 사용 가능
4. 형태소 분석 함수를 제공
5. 띄어쓰기에 덜 민감함 (일본어는 띄어쓰기가 없음) - KoNLP
1. 가장 유명한 형태소 분석기
2. java로 작성된 한나눔 분석기 기반
3. 우리샘, NiaDIC 등 자체 사전
4. 텍스트 분석을 위한 기능들을 제공
5. 친절한 설명서
💾 텍스트 전처리 R 패키지 실습
1. KoNLP 패키지의 SimplePos09() 함수 사용해보기
먼저 N2H4 패키지를 불러와 네이버 기사에 대한 정보를 가져온다. getContent() 함수로 기사 관련 정보를 가져왔다.

가져온 기사에서 기사내용에 해당하는 body를 선택하고 KoNLP 패키지의 SimplePos09() 함수를 적용했다.
> tar <- "https://news.naver.com/main/ranking/read.nhn?mode=LSD&mid=shm&sid1=001&oid=437&aid=0000261701&rankingType=RANKING"
> getContent(tar) %>%
+ select(body) %>%
+ SimplePos09()
$백신
[1] "백신/N"
$접종
[1] "접종/N"
$후
[1] "후/N"
$혈전
[1] "혈전/N"
$`현상,`
[1] "현상/N+,/S"
$국내
[1] "국내/N"
$`2번째`
[1] "2번/N+째/X"
$신고접종한
[1] "신고접종한/N"
$백신
[1] "백신/N"
$종류
[1] "종류/N"
$등
[1] "등/N"
$자세한
[1] "자세한/N"형태소 단위로 잘 끊어진 걸 볼 수 있다.
2. 형태소 토큰 단위 데이터 처리
##형태소 토큰 단위 데이터 처리
getAllComment("https://news.naver.com/main/ranking/read.nhn?mode=LSD&mid=shm&sid1=001&oid=437&aid=0000261701&rankingType=RANKING") %>%
#사용자 아이디와 댓글 컬러만 선택하고
select(userName, contents) %>%
#댓글 컬럼을 형태소 단위로 쪼개
#pos라는 컬럼으로 출력
unnest_tokens(pos, contents, token = SimplePos09) %>%
#사용자별로 그룹 지어서
group_by(userName) %>%
#pos 결과물의 순서 보장을 위해 순서 값 추가
mutate(pos_order = 1:n()) ->
pos_res> pos_res
# A tibble: 8,357 x 3
# Groups: userName [530]
userName pos pos_order
<chr> <chr> <int>
1 thre**** 국내/n 1
2 thre**** 생산/n+이/j+라/e 2
3 thre**** 유럽에서/n 3
4 thre**** 생산한/n 4
5 thre**** 것/n+과/j 5
6 thre**** 다르/p+다고/e+요/j 6
7 thre**** ?/s 7
8 thre**** 백신/n 8
9 thre**** 제조/n+가/j 9
10 thre**** 무슨/m 10
# ... with 8,347 more rows3. 불용어 제거
영어에서는 stop word 사전 등을 사용해 필요없는 단어를 지우지만, 한국어의 경우에는 도메인마다 stop word 사전을 따로 만들어줘야 한다. 이는 굉장히 비효율적이므로 다른 방법을 사용한다. 명사, 형용사, 동사를 빼고 다 버리면 불용어 처리한 것과 유사한 효과가 나타난다.
먼저 명사만 가져온다.
##불용어 제거
#명사
library(stringr)
pos_res %>%
#우선 'filter()'와 'str_detect()' 함수를 활용하여 명사(n)만 추출
filter(str_detect(pos, "/n")) %>%
#형태소 정보를 제거(정규표현식: 굉장히 복잡함)
mutate(pos_done = str_remove(pos, "/.*$")) ->
n_done> n_done
# A tibble: 4,968 x 4
# Groups: userName [528]
userName pos pos_order pos_done
<chr> <chr> <int> <chr>
1 thre**** 국내/n 1 국내
2 thre**** 생산/n+이/j+라/e 2 생산
3 thre**** 유럽에서/n 3 유럽에서
4 thre**** 생산한/n 4 생산한
5 thre**** 것/n+과/j 5 것
6 thre**** 백신/n 8 백신
7 thre**** 제조/n+가/j 9 제조
8 thre**** 신발/n 11 신발
9 thre**** 생산/n+이/j+ㄴ/e 12 생산
10 thre**** 줄/n 13 줄
# ... with 4,958 more rows실제로 filter와 str_detect 함수를 사용해 명사만 추출해보았다.
예를 들어, 명사+조사로 이루어진 단어의 경우 정규표현식에 의해 조사가 제거되고 명사만 남은 걸 볼 수 있다.
[ 생산이라 → 생산 ] 으로 바뀐 걸 확인할 수 있다.
이제 명사, 형용사, 동사를 모두 가져온다. 명사는 n, 동사/형용사는 p로 표시하고, 형태소 분석 후 한 글자는 전후 맥락 없이 의미를 파악 하기 어렵기 때문에 제거한다.
#형용사, 동사
pos_res %>%
filter(str_detect(pos, "/p")) %>%
mutate(pos_done = str_replace_all(pos, "/.*$", "다")) ->
p_done
bind_rows(n_done, p_done) %>%
arrange(pos_order) %>%
filter(nchar(pos_done) > 1) %>%
select(userName, pos_done) ->
pos_done
pos_done> head(pos_done, 20)
# A tibble: 20 x 2
# Groups: userName [20]
userName pos_done
<chr> <chr>
1 thre**** 국내
2 cool**** 사람
3 f4ch**** 그좋은거
4 sgj9**** 시펄
5 chun**** 1호
6 whdt**** 안전한
7 jwaj**** 백신맞고
8 rlag**** 워매워매
9 scot**** 문재앙이
10 msw9**** 문재인씨가
11 kash**** 연관
12 plai**** ~러시아게임
13 a101**** 혈전
14 ohso**** 피가굳으면
15 rlgh**** 솔직하자
16 yhay**** 혈전
17 rosi**** 우리나라
18 nabi**** 계속해서
19 peri**** 문죄인
20 boar**** 진짜 4. string 함수 설명
str_detect() : 글자 데이터 내에 찾고자 하는 글자가 있는지를 T/F로 알려줌
str_detect(
string = 글자 데이터,
pattern = 찾고자 하는 글자,
negate = FALSE # 조건에 맞는 경우 or 그 반대의 결과를 받을 것을 지정
)
str_replace_all() : 찾고자 하는 글자를 원하는 글자로 바꿔줌
str_replace_all(
string = 글자 데이터,
pattern = 찾고자 하는 글자,
replacement = 찾은 글자가 바뀌게 될 글자
)
str_length() : 글자 데이터를 받아서 글자수를 알려줌 (baseR의 n차 함수 사용해도 똑같음)
str_count(
string = 세고자 하는 글자
)5. 정규표현식
글자를 다루는데 유용한 기능을 제공 (외울 수 없음. 자주 보고 참고하는 정도)
- ^ : 이걸로 시작함
- $ : 이걸로 끝남
- . : 임의의 글자 하나
- ? : 앞에 있는 문자가 없거나 하나
- + : 앞에 있는 문자가 하나 이상
- * : 앞에 있는 문자가 없거나 하나 이상
mrchypark.github.io/dabrp_classnote3/class4#1
6. stringr 패키지 연습
1. str_detect() 함수를 사용해 댓글(contents)에 "백신" 글자가 포함되어있는 댓글 찾기
610개의 댓글 중 222개의 댓글로 필터링된 걸 볼 수 있다.
#1. str_detect() 함수를 사용해서 댓글(contents)에 백신 글자가 포함되어 있는 댓글을 찾으세요
getAllComment("https://news.naver.com/main/ranking/read.nhn?mode=LSD&mid=shm&sid1=001&oid=437&aid=0000261701&rankingType=RANKING") %>%
select(userName, contents) -> tar
tar %>%
filter(str_detect(contents, "백신"))> tar
# A tibble: 610 x 2
userName contents
<chr> <chr>
1 alsw**** "자자 재앙이랑 정수기 드가자~~~~~~~~ 맞으러가자으ㅏ~~~~ 화이자 맞으면 턱주가리 돌려버린다 ^^"
2 catf**** "고려대 감염내과 돌팔이들 뭐하냐? AZ 백신 접종 후\n 혈전 생기지 않는다고 반박보도 내놓아야지~"
3 hj89**** "난 절대 안맞을란다"
4 lind**** "사람이 아예안죽었으면 모를까... k방역이라는둥 자화자찬좀 하지 마세요.. 다른나라랑 비교도 하지 마세요.. 죽는사람이 없어야 되는게 최우선입니다. 다수를 위한 논리랍시고 핑계대지마시구요"~
5 verk**** "문씨가 안맞은 이유가 있구나?"
6 love**** "다른나란 중지하는데 나는 안맞고싶다 화이자 주세요 !! 의료진들은 화이자주고 국민들은 싸구려 아.제 주고.."
7 qord**** "정은경 애는 왜 몇일동안이나 혈전이상증상을 숨겼는가??"
8 skyc**** "노동자 한명 죽으면 난리치는 넘\n백신 부작용으로 죽으면 개죽음"
9 redh**** "어차피 복지부는 인과관계없다고 할것입니다 포기하셔요 아무리 이상있다하고 뭐있다해도 그걸 복지부나 정부에서 인정할수 없겠죠..만일 인정하는순간 아스트라백신접종도 외국사례처럼 일시중지나 검토가 필요한데 우리나라 아스트라백신의존도가 다른나라에 비해 높~
10 dada**** "국민생명으로장난치는놈들전부쳐죽00한다"
# ... with 600 more rows
> tar %>%
+ filter(str_detect(contents, "백신"))
# A tibble: 222 x 2
userName contents
<chr> <chr>
1 catf**** "고려대 감염내과 돌팔이들 뭐하냐? AZ 백신 접종 후\n 혈전 생기지 않는다고 반박보도 내놓아야지~"
2 skyc**** "노동자 한명 죽으면 난리치는 넘\n백신 부작용으로 죽으면 개죽음"
3 redh**** "어차피 복지부는 인과관계없다고 할것입니다 포기하셔요 아무리 이상있다하고 뭐있다해도 그걸 복지부나 정부에서 인정할수 없겠죠..만일 인정하는순간 아스트라백신접종도 외국사례처럼 일시중지나 검토가 필요한데 우리나라 아스트라백신의존도가 다른나라에 비해 높~
4 wjsw**** "살인무기 수준이네 백신 겁나 무섭다 ㄷㄷㄷ"
5 appl**** "3상 임상실험도 끝나지 않은 백신을 맞추고 있다.함부로 맞지마라.한국인들은 마루타가 아니다."
6 redh**** "복지부 질병본부처 담당자들이 아스트라백신을 왜 접종안하죠? 국민들에게는 백신 이상없다고 하거선 정작 복지부에서는 아무도 접종안하는군요 사망자나올떄마다 백신과 관계없다 기절질환이다 아니면 다른변명으로 사망한것 같다 뭐 좋읍니다 다좋은데 중요한것은 ~
7 prol**** "국민의 안전성을 위해 백신의 부작용을 면밀히 검토하겠습니다.\n전세계적으로 AZ백신 주사후 사망 증가하자 선진국에서는 일시적 사용중지결정\n문재인 보유국에서는 아직 확실한 증거가 없다고 계속 주사중..ㅋㅋ"~
8 erbi**** "백신과 연관성 없다니 접종이익을 위해 문재인부터 맞히자."
9 appl**** "3상 임상실험도 마치지 못한 백신을 맞추는 이유가 뭐지? 문재앙이 한국인들을 전부 학살해서\n중공에 나라를 바치기 위한게 아닌가?"
10 phb0**** "백신 진실 콘서트 안하냐? 문재인 나와 안외치냐? 죽음의 진실을 밝히는 프로그램 안하냐? 촛불 안드냐? 본인들이 생각해도 그때 그때 다른거 같지? 진영에 기울고 진실은 외면하고 우리나라 사람들 아직 많이 멀었다 문재인보유국이라며 그분 아니면 저 ~
# ... with 212 more rows2. str_remove_all() 함수를 이용해 댓글의 띄어쓰기를 전부 없애보기
str_remove_all() 함수를 사용해야 모든 댓글의 띄어쓰기가 제거된다. (str_remove() 함수는 첫 행만 삭제됨)
> tar %>%
+ mutate(contents=str_remove_all(contents, " "))
# A tibble: 615 x 2
userName contents
<chr> <chr>
1 gooo**** "복골복~~:Az가즈아"
2 dbap**** "23일전에접종중단발표하겠지!!..."
3 shp5**** "전문가님들에게여쭤봅니다~~~제조번호가다르다고아스트라제네카가다른백신이될수있나요????"
4 yjkg**** "부작용보상100억해도되겠는데너무적게했어...인과성이없는걸로나올테니보상할일이없자나"
5 dudq**** "사실상전국민러시안룰렛"
6 dlag**** "정은경이아재백신처맞고혈전생겼으면좋겠다"
7 alsw**** "자자재앙이랑정수기드가자~~~~~~~~맞으러가자으ㅏ~~~~화이자맞으면턱주가리돌려버린다^^"
8 catf**** "고려대감염내과돌팔이들뭐하냐?AZ백신접종후\n혈전생기지않는다고반박보도내놓아야지~"
9 hj89**** "난절대안맞을란다"
10 verk**** "문씨가안맞은이유가있구나?"
# ... with 605 more rows3. 형태소 분석을 하여 결과를 pos 컬럼으로 추가하기
7. 띄어쓰기가 잘못 되어있을 때? - KoSpacing 패키지
KoSpacing은 파이썬 패키지를 R로 불러와 사용하는 거라 아나콘다를 설치해줘야 한다. (설치 나중에 ^^)
library(KoSpacing)
spacing("롯데마트가판매하고있는흑마늘양념치킨이논란이되고있다.")💾 텍스트 마이닝 지표
1. 단어 출현 빈도 : 단순히 단어가 나타난 횟수를 세서 확인 (count)
2. 동시 출현 빈도 : 기준 단어와 함께 나타난 단어들과 그 횟수를 세서 확인 (공빈도)
3. tf-idf : 전체 문서에서 나타난 횟수와 개별 문서에서 나타난 횟수로 만든 지표 (Term x within document y)
4. 감성분석 : 단어를 점수화한 감성사전을 사용하여 점수를 합산하여 만든 지표
1. 단어 출현 빈도 계산
count() 함수는 데이터에서 총 몇 번 나왔는지 세어주는 집계함수. group_by()와 함께 사용해 각 사용자별 단어의 출현 횟수를 구할 수 있다.
library(dplyr)
pos_done %>%
count(pos_done, sort=T) ->
wn
wncount()로 빈도 테이블을 만들면, wordcloud 패키지를 사용해 워드클라우드를 만들 수 있다. {showtext} 패키지를 출력결과물의 폰트를 설정하기 위한 패키지로 Google Fonts 에서 폰트 데이터를 받아와서 출력물에 사용할 수 있다.
library(wordcloud)
library(showtext)
font_add_google("Noto Sans", "notosans")
showtext_auto()
wn %>%
with(wordcloud(pos_done, n, family = "notosans"))예제로 다음과 같은 과정을 처리해본다.
1. tar의 contents 컬럼을 pos() 함수로 형태소 분석을 진행해주세요.
2. 그 중 명사만 남기고, 형태소 정보는 지워주세요. 한글자 명사도 지워주세요.
3. count() 함수를 이용해서 단어 출현 빈도를 계산해 주세요.
4. wordcloud를 만들어 주세요.
5. 다른 색 조합으로 시도해 주세요.
6. group_by()를 활용하여 각 연설문 별로 단어 출현 빈도를 계산해주세요.
7. 각 댓글에서 "우리"가 몇 번 사용되었는지 확인해주세요.
> tar %>%
+ filter(str_length(contents) < 200) %>%
+ unnest_tokens(pos, contents, token=SimplePos09) %>%
+ #2. 그 중 명사만 남기고, 형태소 정보는 지워주세요.
+ filter(str_detect(pos, "/n")) %>%
+ mutate(pos_done = str_remove(pos, "/.*$")) %>%
+ #한글자 명사도 지워주세요
+ filter(str_length(pos_done) > 1) %>%
+ #3. 단어출현빈도 계산
+ count(pos_done, sort=T) %>%
+ with(
+ wordcloud(pos_done, n)
+ )
# A tibble: 2,394 x 2
pos_done n
<chr> <int>
1 백신 191
2 사람 74
3 접종 63
4 부작용 53
5 혈전 43
6 국민 41
7 정부 38
8 ^ㅋ 36
9 기저질환 34
10 중단 28
# ... with 2,384 more rows형태소 분석을 하고, 단어출현빈도를 계산해 4번 워드클라우드 만들기까지 하면 이런 결과가 나온다.

library(N2H4)
library(dplyr)
getAllComment("https://news.naver.com/main/ranking/read.nhn?mode=LSD&mid=shm&sid1=001&oid=437&aid=0000261701&rankingType=RANKING") %>%
select(userName, contents) -> tar
tar
library(tidytext)
library(KoNLP)
library(stringr)
library(wordcloud)
#1. tar의 contents 컬럼을 pos() 함수로 형태소 분석을 진행해주세요
tar %>%
filter(str_length(contents) < 200) %>%
unnest_tokens(pos, contents, token=SimplePos09) %>%
#2. 그 중 명사만 남기고, 형태소 정보는 지워주세요.
filter(str_detect(pos, "/n")) %>%
mutate(pos_done = str_remove(pos, "/.*$")) %>%
#한글자 명사도 지워주세요
filter(str_length(pos_done) > 1) -> pos_d
pos_d
#3. 단어출현빈도 계산
#4. wordcloud를 만들어 주세요
pos_d %>%
count(pos_done, sort=T) %>%
with(
wordcloud(pos_done, n)
)
#6. group_by()를 활용하여 각 유저별로 단어 출현 빈도를 계산해주세요.
#7. 각 댓글에서 "백신"가 몇 번 사용되었는지 확인해주세요.
pos_d %>%
select(-pos) %>%
group_by(userName) %>%
count(pos_done, sort=T) %>%
filter(pos_done == "백신")# A tibble: 153 x 3
# Groups: userName [153]
userName pos_done n
<chr> <chr> <int>
1 kash**** 백신 4
2 vtkd**** 백신 4
3 kee7**** 백신 3
4 name**** 백신 3
5 optc**** 백신 3
6 sile**** 백신 3
7 top0**** 백신 3
8 adon**** 백신 2
9 appl**** 백신 2
10 choi**** 백신 2
# ... with 143 more rows최종적으로 각 유저별로 단어출현빈도를 계산하고, 각 댓글에서 "백신"이라는 단어가 몇번 사용되었는지 확인했다.
2. 동시출현 빈도 계산
pairwise_count() 함수는 그룹 단위 내에서 단어가 동시에 출현한 횟수를 세어주는 함수로, 보통 문장 단위를 그룹으로 처리한다.
install.packages("widyr", dependencies = T)
pairwise_count(
tbl = 대상 데이터,
item = 갯수를 새어야 할 컬럼,
feature = 함께 출현했다고 판단할 단위 그룹,
sort = 출현 횟수 단위로 정렬할지
)
filter() 함수로 기준 단어를 조회하면 함께 자주 나오는 단어와 그 빈도를 확인할 수 있다. (단일빈도보다 얻을 인사이트가 많음)
pw %>%
filter(item1 == "우리")ggplot을 이용해 시각화해볼 수도 있다.
공출현빈도는 대선출마에서 트위터 텍스트 네트워크를 구성할 때 쓰인다. (네트워크 시각화)
이러한 출현빈도와 시각화기법은 도메인 지식이 존재할 때 보조도구로써 활용될 수 있다.
3. tf-idf
tf : 전체 문서 내의 단어 빈도
idf : 단어를 가지는 문서 비율의 역수

불용어 사전을 안 쓰고도 적용한것과 같은 효과가 있다.
여러 명이 공통적으로 말한 단어는 역수를 취해 페널티(-)를 주고, 특정 사람만 말한 단어는 가중치(+)를 주는 방식이다.
bind_tf_idf() 함수가 tf, idf, tf-idf 점수 모두를 제공하며 문서 단위의 정의가 매우 중요하다.
보통 각 연설문, 개별 뉴스 본문 등을 하나의 문서로 정의한다. tf-idf가 높을수록 각 문서에서 특별한 의미를 지니는 것으로 판단할 수 있다.
library(tidyverse)
library(tidytext)
tar %>%
mutate(id = as.numeric(1:n())) %>%
unnest_tokens(pos, contents, token = SimplePos09) %>%
select(id, pos) %>%
filter(str_detect(pos, "/n|/v(v|a)")) %>%
mutate(pos = str_remove_all(pos, "/.*$")) %>%
filter(nchar(pos) > 1) %>%
group_by(id) %>%
count(pos) ->
tfidf_tar
tfidf_tar %>%
bind_tf_idf(pos, id, n) %>%
arrange(desc(tf_idf))그룹별로 단순빈도계산한 것을 바탕으로 tf-idf 계산을 한다
# A tibble: 4,703 x 6
# Groups: id [656]
id pos n tf idf tf_idf
<dbl> <chr> <int> <dbl> <dbl> <dbl>
1 2 안마 1 1 6.49 6.49
2 12 이럴줄 1 1 6.49 6.49
3 82 안맞을란 1 1 6.49 6.49
4 87 국민생명으로장난치는놈들전부쳐죽00한 1 1 6.49 6.49
5 114 살인백신=좌파백 1 1 6.49 6.49
6 186 sk바이오사이언스때문인감 1 1 6.49 6.49
7 229 어떻 1 1 6.49 6.49
8 250 쪽팔리신거지 1 1 6.49 6.49
9 258 문재앙님이 1 1 6.49 6.49
10 298 az야 1 1 6.49 6.49
# ... with 4,693 more rows1. 새롭게 댓글별 id를 id 컬럼으로 추가해주세요.
2. 문장별 id를 유지한 채로 pos() 함수를 사용하여 형태소 분석을 진행해 주세요.
3. 명사(/n), 동사(/vv), 형용사(/va)인 형태소만 가져와 주세요.
4. 명사는 형태소 정보를 제거하고, 형용사와 동사는 형태소 정보를 제거한후 뒤에 다를 붙여주세요.
5. 한 글자는 제거해 주세요.
6. 댓글 별로 형태소 단위 빈도를 계산해 주세요.
7. bind_tf_idf() 함수를 사용해서 tf, idf, tf-idf 를 계산해주세요.
8. 각 댓글 별로 tf-idf 점수가 가장 높은 단어를 확인하세요.
9. 각 댓글 별로 tf-idf 점수가 가장 높은 3개 단어씩을 확인하세요.
tar %>%
mutate(id = as.numeric(1:n())) %>%
unnest_tokens(psdone, contents, token=SimplePos09) %>%
filter(str_detect(psdone, "/n|/v(v|a)")) -> nvp_set
nvp_set %>%
filter(str_detect(psdone, "/n")) %>%
mutate(psdone = str_replace_all(psdone, "/.*$", "")) -> ndone
nvp_set %>%
#negate 옵션으로 n 외의 다른 거(vv, va) 필터
filter(str_detect(psdone, "/n", negate = T)) %>%
mutate(psdone = str_replace_all(psdone, "/.*$", "")) -> vdone
bind_rows(ndone, vdone) %>%
arrange(id) %>%
filter(str_length(psdone) > 1) %>%
group_by(id) %>%
count(psdone, sort=T) %>%
bind_tf_idf(psdone, id, n) %>%
top_n(tf_idf, 3) %>%
arrange(desc(tf_idf))# A tibble: 944 x 6
# Groups: id [380]
id psdone n tf idf tf_idf
<dbl> <chr> <int> <dbl> <dbl> <dbl>
1 2 안마 1 1 6.49 6.49
2 12 이럴줄 1 1 6.49 6.49
3 82 안맞을란 1 1 6.49 6.49
4 87 국민생명으로장난치는놈들전부쳐죽00한 1 1 6.49 6.49
5 114 살인백신=좌파백 1 1 6.49 6.49
6 186 sk바이오사이언스때문인감 1 1 6.49 6.49
7 229 어떻 1 1 6.49 6.49
8 250 쪽팔리신거지 1 1 6.49 6.49
9 258 문재앙님이 1 1 6.49 6.49
10 298 az야 1 1 6.49 6.49
# ... with 934 more rows4. 감성분석
각 단어의 감성 사전을 구축해 점수를 주는 방식이다. 한글의 특성상, 형태소이며 ngram에 점수를 부여하는 것이 가장 효과적이다. 단순한 형태로는 unigram의 형태소에 점수나 종류를 부여하는 것이 있다.
개별 단어의 점수를 부여한 뒤, 문장 단위로 합산하여 계산한다. 합산으로 0에 가까운 값이 나올 수도 있으므로 점수를 부여받은 단어의 개수 등도 고려할 필요가 있다. 안정적으로 기구축된 한글 사전을 찾기 어렵다.
- KnuSentiLex는 군산대에서 기존 사전들을 참조, 활용해 18년에 구축한 감성사전이다. 구조가 단순하고 이모티콘 등을 추가한 점이 장점인 반면, 형태소 형식이 아니므로 점수의 신뢰도가 낮은 편이다.
- KOSAC은 서울대에서 13년에 구축한 감성사전으로 구조가 복잡하고 점수를 내기 어렵지만 12년에 구축한 감성 스키마를 따르고 있어 다양한 감성 정보를 얻을 수 있다.
# remotes::install_github("mrchypark/KnuSentiLexR")
library(KnuSentiLexR)
tar %>%
unnest_tokens(sent, contents, token = "sentences") %>%
filter(nchar(sent) < 20) %>%
select(sent) ->
senti_tar- senti_score() 함수는 문장을 unigram부터 3-gram까지 작성한 후, 감성사전에 점수를 합산하여 문장 점수를 계산
- senti_magnitude() 함수는 몇 개의 ngram이 점수화되었는지를 계산
- dic 객체가 word, polarity 컬럼을 가지고 있는 감성 사전임
- 구글의 한글감성분석 API가 있지만 KnuSentiLex 유사한 정도의 쓰레기 성능이다..
KoNLP 패키지 설치 오류 해결 방법
R에 KoNLP설치 오류가 뜬다구요?
안녕하세요! 여러분,,많은 분들이 유튜브에 R에서 KoNLP설치에 관한질문을 해주셔서 해결방안을 알...
blog.naver.com
'Data Science' 카테고리의 다른 글
| 사례연구: TF-IDF 기반 문서 검색 (내용기반 Content-Based 검색) (0) | 2021.06.10 |
|---|---|
| 추천시스템과 협업 필터링 (0) | 2021.06.09 |
| [Jupyter Notebook] 테마 및 폰트 설정하기 (0) | 2021.05.27 |